Мы уже писали о решении EMC VPLEX, которое позволяет организовать катастрофоустойчивую архитектуру хранилищ для виртуальных машин за счет организации синхронного распределенного виртуального тома (Disrtibuted Virtual Volume).
Семейство продуктов EMC VPLEX с операционной системой EMC GeoSynchrony является решением по объединению на основе сети SAN. Технология EMC VPLEX Metro позволяет объединить дисковые ресурсы массивов, находящихся на двух географически разделенных площадках в единый пул хранения. Со стороны серверов ESX / ESXi на обеих площадках доступен один виртуальный логический том, который обладает свойством катастрофоустойчивости, поскольку данные физически хранятся и синхронизируются на обеих площадках.
Данная технология интегрирована с технологией отказоустойчивости VMware HA за счет поддержки структуры vSphere Metro Storage Cluster, что позволяет использовать их совместно для обработки различных вариантов сбоев в виртуальной инфраструктуре. К тому же, EMC VPLEX - это единственное сертифицированное VMware решение для организации географически "растянутых" кластеров VMware HA.
В географически разнесенных ЦОД, хранилища которых синхронизированы с помощью VPLEX, есть важная проблема – является ли нарушение связи между узлами кластеров VPLEX следствием сбоя сети или сбоя на площадке. Она затрагивает и кластеры VPLEX, которые находятся в различных географических точках. Система EMC VPLEX обрабатывает сбой сети путем автоматического прекращения всех операций ввода-вывода в устройстве («отключение») на одной из двух площадок в зависимости от набора преопределенных правил. Операции ввода-вывода в то же устройство на другой площадке продолжают выполняться в обычном режиме. Поскольку правила применяются к каждому устройству в отдельности, в случае разделения сети активные устройства могут присутствовать на обеих площадках. Для предотвращения этого используется Cluster Witness - компонент на сторонней площадке, отвечающий за мониторинг доступности основной и резервной площадки.
При отказе различных компонентов ИТ-инфраструктуры и каналов связи могут возникнуть различные ситуации как для кластера VPLEX, так и для кластера VMware HA, которые успешно обрабатываются и теоретически весьма мало ситуаций, которые могут привести к потере данных. Однако есть ситуации (и они всегда будут в распределенных ЦОД - именно потому RTO=0 это Objective, а не Requirement), когда нельзя автоматизировать операции по восстановлению и требуется вмешательство администратора, который выполнит наиболее правильное действие.
Вот как VPLEX совместно с HA обрабатывают различные варианты сбоев:
Сценарий
Поведение VPLEX
Влияние на кластер VMware HA
Отказ одного из путей порта
VPLEX back-end
(BE) к дисковому массиву.
VPLEX прозрачно переключится на альтернативный путь, без влияния на работу распределенных виртуальных томов (Distributed Virtual Volumes).
Отсутствует.
Отказ одного из путей к порту VPLEX front-end
(FE) от хост-сервера.
Сервер ESXi за счет встроенного механизма работы по нескольким путям переключится на резервный путь к распределенным виртуальным томам.
Отсутствует.
Выход из строя массива
на основной площадке.
VPLEX продолжит обслуживать виртуальные тома, используя дисковый массив резервной площадки. Когда основной дисковый массив восстановится после сбоя, тома основного дискового массива будут автоматически синхронизированы с резервного.
Отсутствует.
Выход из строя массива на резервной площадке.
VPLEX продолжит обслуживать виртуальные тома, используя дисковый массив основной площадки. Когда резервный дисковый массив восстановится после сбоя, тома резервного дискового массива будут автоматически синхронизированы с основного.
Отсутствует.
Выход из строя одного из устройств VPLEX Director.
VPLEX продолжит обслуживать виртуальные тома, перенаправив запросы на другие директоры кластера VPLEX.
Отсутствует.
Полная потеря основной площадки (катастрофа), включая все хосты ESXi и компоненты кластера VPLEX (обнаруживается с помощью Cluster Witness).
VPLEX продолжит обслуживать запросы ввода-вывода на дисковом массиве резервной площадки. Когда основная площадка восстановится, виртуальные тома будут синхронизированы с резервной площадки.
Виртуальные машины основной площадки будут перезапущены на хостах резервной площадки.
Полная потеря резервной площадки (катастрофа), включая все хосты ESXi и компоненты кластера VPLEX (обнаруживается с помощью Cluster Witness).
VPLEX продолжит обслуживать запросы ввода-вывода на дисковом массиве основной площадки. Когда резервная площадка восстановится, виртуальные тома будут синхронизированы с основной площадки.
Виртуальные машины резервной площадки будут перезапущены на хостах основной площадки.
Множественный выход из строя хост-серверов в рамках одной из площадок.
Отсутствует
Механизм VMware HA перезапустит виртуальные машины на оставшихся хостах кластера HA.
Выход из строя сети сигналов доступности в рамках одной из площадок.
Отсутствует.
HA продолжит обмен сигналами доступности через общие хранилища (см. тут), что не повлечет за собой аварийного восстановления.
Все пути к хосту ESXi находятся в состоянии APD (All Paths down) – т.е. временно отсутствует доступ к хранилищам (виртуальным томам).
Отсутствует.
В этом случае необходимо перезапустить сервер ESXi, что приведет к перезапуску виртуальных машин в кластере HA на других хост-серверах кластера HA.
Разрыв канала репликации между устройствами VPLEX при сохранении сети управления.
На резервной площадке VPLEX переводит виртуальные тома в режим I/O Failure (что запрещает работу с ними). На основной площадке виртуальные тома продолжают оставаться доступными виртуальным машинам.
На основной площадке виртуальные машины продолжают функционировать. На резервной площадке виртуальные машины получают ошибку ввода-вывода и выключаются. Механизм VMware HA (VM Monitoring) восстанавливает их на резервной площадке.
Сбой кластера VPLEX (компоненты кластера на обеих площадках недоступны, но хосты ESXi не испытывают проблем работы по SAN и СПД).
Запросы ввода-вывода для всех виртуальных томов продолжат обслуживаться на основной площадке.
Хосты ESXi на резервной площадке перейдут в состояние APD. Это потребует их перезагрузки для восстановления виртуальных машин.
Одновременный полный выход из строя обеих площадок.
После восстановления площадок VPLEX продолжит обслуживать запросы ввода-вывода (в первую очередь следует запустить дисковые массивы на обеих площадках).
Хосты ESXi должны быть включены только после того, как компоненты VPLEX будут восстановлены, а виртуальные тома синхронизированы. При включении хостов ESXi виртуальные машины будут восстановлены механизмом VMware HA.
Выход из строя одного из директоров VPLEX на одной из площадок, а также выход дискового массива на противоположной площадке (резервная площадка для виртуального тома).
Оставшиеся директоры кластера VPLEX продолжат обслуживать доступ к виртуальным томам, используя дисковый массив, являющийся для них основным.
Отсутствует
Разрыв сети сигналов доступности (heartbeat) на одной из площадок и разрыв коммуникаций VPLEX между площадками (отличие от выхода из строя площадки понимает Cluster Witness).
VPLEX прекращает обслуживать запросы ввода-вывода для виртуальных томов, у которых дисковые массивы помечены как резервные. Обмен продолжится только с дисковыми массивами, являющимися основными для виртуальных томов.
На основной площадке виртуальные машины продолжат исполняться. Для VMware HA – это ситуация «split-brain» (хосты резервной площадки считают себя оставшимися работоспособными в кластере и пытаются включить виртуальные машины). При включении ВМ на хостах резервной площадки будет получена ошибка ввода-вывода. В этой ситуации необходимо вручную перерегистрировать виртуальные машины резервной площадки на основной.
Том VPLEX оказывается недоступен (например, случайно удален из консоли управления).
VPLEX продолжит обслуживать запросы ввода-вывода с резервной площадки, где том доступен.
Все хосты ESXi работающие с томом VPLEX получают ошибку ввода-вывода и переходят в состояние PDL (Permanent Device Loss). В результате компонент VM Monitoring останавливает виртуальные машины, после чего они запускаются на хостах другой площадки.
Разрыв соединения между компонентами VPLEX на обеих площадках и одновременных выход из строя соединения VPLEX Cluster Witness к основной площадке.
VPLEX прекращает обслуживать запросы ввода-вывода к виртуальным томам на резервной площадке и продолжает работу с томами основной площадки.
Виртуальные машины на резервной площадке завершат работу по ошибке ввода-вывода, они могут быть вручную зарегистрированы и запущены на резервной площадке.
Разрыв соединения между компонентами VPLEX на обеих площадках и одновременных выход из строя соединения VPLEX Cluster Witness к основной площадке.
VPLEX прекращает обслуживать запросы ввода-вывода к виртуальным томам на основной площадке и продолжает работу с томами резервной площадки.
Виртуальные машины на основной площадке завершат работу по ошибке ввода-вывода, они могут быть вручную зарегистрированы и запущены на резервной площадке.
Сбой компонента VPLEX Cluster Witness.
VPLEX продолжает обслуживать запросы ввода-вывода на обеих площадках.
Отсутствует.
Сбой компонента VPLEX Management Server на одной из площадок.
Отсутствует.
Отсутствует.
Отказ сервера управления виртуальной инфраструктурой VMware vCenter
Отсутствует.
На механизм VMware HA и восстановления виртуальных машин это не повлияет. Однако правила размещения и балансировки виртуальных машин по хост-серверам прекратят работать.
Как видите, все ситуации обрабатываются разумно и корректно. Тут обязательным должно быть наличие VPLEX Cluster Witness, который отличит выход из строя линков между ЦОД от выхода из строя одного из ЦОД, о чем он скажет им обоим.
Также надо отметить, что полной автоматизации восстановления тут нельзя добиться, как говорится, "by design".
Многие из вас знают продукт номер 1 для резервного копирования виртуальных машин VMware vSphere - Veeam Backup and Replication. Мы уже много писали как о функциональности Veeam Backup and Replication 5, так и о новых возможностях, которые появляются в Veeam Backup and Replication 6. В среду, 30 ноября, должен состояться релиз новой версии продукта, поэтому постараемся в этой статье собрать все новые функции, улучшения и нововведения Veeam Backup and Replication 6 (обратите также внимание на повышение цен на продукт с 1 декабря).
Приведенная ниже информация основана на документе "Veeam Backup & Replication. What's new in v6", который вы можете почитать в оригинале для понимания всех аспектов новых возможностей этого средства для резервного копирования виртуальных машин.
Новые ключевые возможности и улучшения Veeam Backup and Replication 6:
Enterprise scalability: улучшенная архитектура продукта позволяет производить развертывание в удаленных офисах и филиалах, а также для больших инсталляций. Теперь появилось несколько backup proxy серверов для крупных окружений (data movers), которые могут распределять между собой нагрузку в процессе резервного копирования, а управляет процессом сервер Veeam Enterprise Manager. Виртуальные машины динамически назначаются proxy-серверам с учетом алгоритма балансировки нагрузки, что снижает затраты на администрирование инфраструктуры РК. Также увеличена производительность для резервного копирования, репликации и восстановления по WAN-каналам.
Advanced replication: в некоторых случаях скорость репликации выросла до 10 раз, а также появится Failback (обратное восстановление виртуальной машины после возобновления работы отказавшего хоста с ВМ) с возможностью синхронизации дельты (различия данных с момента отказа основной машины на основном сервере и хранилище - Failover). Кроме того, поддерживается репликация в thin provisined-диски на целевой сервер. Это сильная заявка на победу над VMware SRM 5 (в издании Standard) для небольших компаний, где серверов не много и нужно укладываться в небольшие бюджеты. Появилась также возможность создания реплик базового образа для окружений VMware View.
Multi-hypervisor support: полная поддержка Windows Server с ролью Hyper-V и Microsoft Hyper-V Server, а также возможность управления резервным копированием для гипервизоров разных производителей из одной консоли. Одна и та же инсталляция Veeam Backup позволит делать резервные копии и с VMware vSphere, и с Microsoft Hyper-V. При этом лицензирование также единое - один пул лицензий Veeam вы можете распределить между лицензиями на процессоры для хостов ESXi и Hyper-V. Кроме того, появилась поддержка методики Changed Block Tracking для Hyper-V для ускорения процесса инкрементального резервного копирования (отслеживание изменившихся блоков с момента последнего бэкапа).
1-Click File Restore - с помощью 1-Click File Restore можно зайти в Enterprise Manager, выбрать нужный файл и восстановить туда, откуда он был удален (это можно сделать также из результатов поиска файла по резервным копиям). При этом есть разделение ролей - есть тот, кто может файл восстановить (helpdesk), а есть тот, кто открыть. Данная возможность доступна только в Enterprise Edition.
Полный список новых возможностей:
Архитектура Veeam Backup and Replication 6
ESXi-centric processing engine - теперь архитектура продукта полностью опирается на архитектуру ESXi, но в поддержка гипервизора ESX остается в полной мере.
Backup proxy servers - один сервер Veeam Backup может контролировать несколько прокси-серверов, обеспечивающих передачу данных на целевые хранилища. Прокси-серверы не нуждаются в Microsoft SQL
Server и содержат минимальный набор компонентов.
Backup repositories - новая концепция репозиториев резервного копирования (в традиционном РК известная как медиа-серверы), которые хранят настройки задач резервного копирования и параметры целевых хранилищ. Задачи по РК виртуальных машин с помощью медиа-серверов динамически назначаются proxy-серверам с учетом алогоритма балансировки нагрузки.
Windows smart target - в дополнение к Linux target agent, который помогает при резервном копировании в удаленные хранилища, появился также агент для Windows. Этот агент на целевой машине позволяет производить эффективную компрессию и обновлять синтетические резервные копии.
Enhanced vPower scalability - теперь можно использовать несколько серверов vPower NFS. Теперь можно запускать еще больше ВМ напрямую из резервных копий (например, если у вас много ВМ с большими дисками это очень может помочь). Любой сервер РК Veeam или Windows backup repository может быть таким сервером.
Ядро продукта Veeam Backup and Replication 6
Optimization of source data retrieval - теперь учитываются параметры дисковых хранилищ при обращении к виртуальным машинам. Это позволяет до 4-х раз увеличить производительность для одной операции, в зависимости от настроек дискового массива.
Reduced CPU usage - теперь в два раза меньше нагрузка задач на процессор, что позволяет запустить больше задач РК или репликации на одном сервере Veeam Backup или прокси-сервере.
Traffic throttling - теперь доступны опции по регулированию полосы пропускания, которые производятся на базе пары source/target IP. Эти правила могут быть основаны на времени операций - время дня или день недели.
Multiple TCP/IP connections per job - теперь агенты Data Movers могут инициировать соединение по нескольким IP-адресам, что существенно увеличивает скорость резервного копирования. Особенно это эффективно для репликации по WAN-каналам.
WAN optimizations - протокол передачи данных Veeam Backup был существенно доработан в плане производительности для передачи данных по соединениям с большими задержками в канале.
Exclusion of swap files - блоки, относящиеся к файлам подкачки, теперь исключаются из передачи в резервную копию, что существенно увеличивает производительность.
Enforceable processing window - теперь для каждой задачи можно задавать окно РК или репликации (все задачи, не попадающие в это окно завершаются). Также вне рамок окна не разрешается применение снэпшотов, что не позволяет оказывать влияние на производительность ВМ в рабочие часы.
Parallel backup and replication - теперь задачи, относящиеся к одной и той же ВМ, могут быть выполнены параллельно. Например, вы можете запускать ежедневную задачу Full Backup параллельно с работающей задачей репликации.
Улучшения резервного копирования в Veeam Backup and Replication 6
Backup mapping - при создании новой задачи резервного копирования ВМ, ее можно присоединить к уже имеющейся задаче (например, в ней есть уже файлы этой ВМ). В этом случае Full Backup этой ВМ может не потребоваться.
Enhanced backup file format - новый формат метаданных позволяет осуществлять быстрый импорт резервных копий, а также закладывает основу для поддержки новой функциональности в следующих релизах продукта.
Backup file data alignment - данные ВМ, сохраненные в бэкап-файле, могут быть размещены в пределах блоков по 4 КБ. Это увеличивает производительность дедупликации как самого Veeam Backup, так и сторонних технологий дедупликации (например, средствами дискового массива).
Improved compatibility with deduplicating storage - теперь механизм РК оказывает меньшее влияние на предыдущие файлы резервной копии, что улучшает производительность массивов, которые осуществляют пост-процессинг хранимых данных.
Репликация Veeam Backup and Replication 6
New replication architecture - теперь репликация использует двухагентную архитектуру, которая позволяет собирать данные хранилищ ВМ на исходном DR-сайте одним прокси-сервером РК и посылать их напрямую к прокси-серверу резервной площадки (и наоборот), минуя главный сервер Veeam Backup. Поэтому теперь не разницы, где размещать последний.
Replica state protection - теперь инкрементальные задачи репликации больше не обновляют последнюю точку восстановления ВМ. Это позволяет при прерывании задачи не перестраивать последнюю точку восстановления до того, как следующая задача откатит ее к последнему согласованному состоянию, как в прошлых версиях. В версии 6 последняя точка восстановления всегда согласована и ВМ может быть запущена в любой момент.
Traffic compression - за счет новой архитектуры репликации теперь не важно где находится основной сервер РК Veeam, а трафик сжимается намного более эффективно. Кроме того, появились настройки уровня компрессии для передаваемого трафика, что позволяет уменьшить требования к полосе пропускания до 5 раз.
Hot Add replication - теперь прокси-сервер на целевой площадке представляет диски реплики, используя технологию Hot Add. Это уменьшает поток трафика до 4 раз.
1-click automated failback - позволяет произвести обратное восстановление (Failback) виртуальной машины после возобновления работы отказавшего хоста с ВМ с возможностью синхронизации только дельты с момента последнего отказа (Failover), т.е. различия данных с момента отказа основной машины на основном сервере и хранилище) . Перед завершением этого процесса можно проверить ВМ на работоспособность на основной площадке.
1-click permanent failover - возможность в один клик провести все необходимые процедуры по завершению процесса превращения резервной машины в основную, когда в случае отказа основной ВМ она переместилась на резервный сайт.
Active rollbacks - репликация теперь хранит точки восстановления как обычные снапшоты ВМ. Это позволяет откатиться в любую точку на резервной площадке, даже без участия Veeam Backup.
Improved replica seeding - улучшения механизма организации репликации. Теперь репликация использует обычные бэкап-файлы, это позволяет уменьшить размер передаваемых данных, поддерживаются ВМ с тонкими (thin) дисками и многое другое.
Replica mapping - теперь реплицируемую виртуальную машину можно привязать к уже существующей ВМ на резервной площадке (например, ранее для нее использовалась репликация или на резервную площадку ее восстановили из резервной копии). Это позволяет не передавать весь объем данных для создания реплицируемой пары.
Re-IP - теперь можно задать правила автоматического назначения IP-адреса для восстанавливаемой ВМ. Это очень полезно, когда требуется восстановить ВМ на резервную площадку, где действует другая схема IP-адресации, в случае сбоя основной.
Cluster target - задачи репликации теперь поддерживают указание определенного хоста или кластера как целевого для репликации. Это позволяет убедиться в том, что при восстановлении ВМ она окажется доступной (например, на резервной площадке).
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches технологией репликации, что позволяет передавать состояние реплики без дополнительных ручных операций (например, в окружениях с VMware vCloud Director).
Automatic job update - операции failover и failback автоматически обновляют задачу репликации путем исключения из нее ВМ и повторного добавления.
Multi-select operations - в консоли теперь можно выбрать несколько ВМ для операций с репликацией. Например, при массовом выходе из строя хостов можно провести операции failover сразу с несколькими ВМ (аналогично и для failback).
Enhanced job configuration - теперь мастер создания реплицируемой пары поддерживает возможность настройки репликации на уровне vmdk-дисков, а также предоставляет возможность настроить целевые объекты: resource pool, VM folder и virtual network, где будет размещаться реплика и восстанавливаться ВМ.
Миграция виртуальных машин в Veeam Backup and Replication 6
Quick Migration - эта технология позволяет организовать миграцию виртуальной машины между хостами и/или хранилищами путем передачи данных ВМ в фоновом режиме (пока она запущена) и потом на время простоя (переключения) передается только дельта файлов vmdk. Переключение осуществляется с помощью технологии SmartSwitch или просто повторной загрузкой ВМ. По сути, эта функция - аналог vMotion и Storage vMotion, но с небольшим простоем ВМ.
SmartSwitch - эта технология позволяет передать текущее состояние ВМ от исходного хоста и хранилища к источнику на время переключения виртуальной машины между ними (с простоем). При этом процессоры исходного и целевого хостов должны быть совместимы по инструкциями.
Migration jobs - новый тип задач "миграция ВМ". С учетом имеющейся у вас лицензии на VMware vSphere, мастер миграции выполняет одну из следующих задач: VMware vMotion, VMware Storage vMotion, Veeam Quick Migration
with SmartSwitch или Veeam Quick Migration with cold switch. Это позволяет быстро перевести ВМ с хостов, для которых требуется срочное обслуживание или останов (например, электричество выключили, а они на UPS'ах) или перенести ВМ в другой датацентр с минимальным влиянием на доступность сервисов в ВМ.
Instant VM Recovery integration - задачи миграции ВМ теперь оптимизированы для работы с функцией Instant VM Recovery. Если задача миграции обнаруживает, что ВМ переносится из состояния, когда она была мгновенно восстановлена (т.е. дельта размещается на vPower NFS datastore), то постоянная составляющая этой ВМ берется из бэкап-файла, а различия уже с NFS-хранилища для ускорения процесса миграции и оптимизации производительности.
Копирование файлов в Veeam Backup and Replication 6
Support for copying individual file - поддержка копирования отдельных файлов. Задача по копированию файлов теперь поддерживается так же, как и для каталогов.
Восстановление виртуальных машин в Veeam Backup and Replication 6
1-click VM restore - при восстановлении ВМ в исходное размещение (самый частый случай), это может быть сделано в один клик.
Virtual Disk Restore wizard - новый режим восстановления позволяет восстановить отдельные vmdk-диски в их исходное размещение или присоединить к другой или новой ВМ. При этом мастер Virtual Disk Restore может восстанавливать диски как "thin" (т.е. растущими по мере наполнения данными), а также делает все необходимые настройки в заголовочном vmdk-файле.
Hot Add restores - Veeam Backup первым стал поддерживать технологию Hot Add не только для РК, но и для восстановления vmdk-дисков, что позволяет избежать проблем производительности.
Multi-VM restore - возможность восстановления сразу многих ВМ из графического интерфейса, что очень удобно для случаев массовых отказов хранилищ или хост-серверов.
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches и улучшения в интерфейсе по интеграции с ним (что удобно, например, при использовании совместно с vCloud Director).
Network mapping - при восстановлении виртуальных машин на сервер или площадку с другой конфигурацией виртуальных сетей, можно указать новые параметры сетевого взаимодействия.
moRef preservation - при восстановлении ВМ с заменой существующей копии, ее идентификатор сохраняется, что позволяет не перенастраивать задачи Veeam, а также стороннее ПО, работающее с виртуальными машинами по их идентификатору (почти все так и работают).
Восстановление на уровне файлов в Veeam Backup and Replication 6
Support for GPT and simple dynamic disks - теперь восстановление на уровне файлов поддерживает тома GPT и simple dynamic disks.
Preservation of NTFS permissions - опционально при восстановлении файлов Windows можно сохранить владельца и права на них в NTFS.
Индексирование и поиск файлов в резервных копиях Veeam Backup and Replication 6
Optional Search Server - теперь поиск по файлам гостевой ОС работает без Microsoft Search Server. Однако он рекомендуется для больших окружений с сотнями ВМ для лучшей производительности.
Reduced catalog size - размер каталога файловой системы гостевых ОС существенно уменьшился, что позволяет экономить место на сервере Veeam Backup.
User profile indexing - появилась поддержка индексации профиля пользователя в гостевой ОС.
Статистика и отчетность в Veeam Backup and Replication 6
Enhanced real-time statistics - теперь статистика в реальном времени по задачам РК улучшена в плане дизайна, чаще обновляется и более информативна для пользователя.
Improved job reports - отчеты о задачах РК лучше выглядят, имеют дополнительную информацию, включая количество изменившихся данных, уровень компрессии и коэффициент дедупликации.
Bottleneck monitor - в ответ на наиболее частые вопросы о низкой производительности в различных окружениях, Veeam сделала новый компонент, который позволяет выявить узкие места на различных стадиях РК и репликации. Все это отображается в статистике реального времени.
VM loss warning - история задач РК теперь оповещает пользователя о виртуальных машинах, которые раньше бэкапились, а потом задачи РК перестали существовать (например, случайно или намеренно удалили).
Интерфейс пользователя консоли Veeam Backup and Replication 6
Wizard improvements - все мастера были обновлены для возможности быстрой навигации при создании задач РК. Некоторые мастера стали динамическими - т.е. сфокусированными только на той задаче, которую вы хотите выполнить.
VM ordering - мастера резервного копирования и репликации теперь позволяют задать порядок, в котором ВМ должны обрабатываться.
Multi-user access - доступ нескольких пользователей к консоли теперь включен по умолчанию, позволяя нескольким пользователям получить доступ к консоли по RDP на одном сервере.
Веб-интерфейс Enterprise Manager в Veeam Backup and Replication 6
Job editing - в дополнение к управлению задачами, Enterprise Manager позволяет теперь менять их настройки для защищаемых ВМ, бэкап-репозитории, учетную запись гостевой ОС - все прямо из веб-интерфейса.
Job cloning - существующие задачи теперь могут быть клонированы прямо из веб-интерфейса с сохранением всех настроек.
Helpdesk FLR - появилась новая роль "File Restore Operator" в Enterprise Manager, которой делегированы полномочия по восстановлению отдельных файлов. Ее можно назначить персоналу службы help desk. При этом файлы восстанавливаются в их исходное размещение, а персоналу hepl desk можно ограничить возможности их скачивания, и, соответственно, доступа к ним (есть настройки касательно типов файлов и прочее).
FIPS compliance - веб-интерфейс теперь полностью совмести с стандартом FISP.
Design improvements - веб-интерфейс имеет множество улучшений в плане юзабилити и дизайна.
Улучшения технологии SureBackup в Veeam Backup and Replication 6
Improved DC handling - теперь улучшена работа с контроллерами домена в ситуациях, когда он оказывается изолированным в окружениях с несколькими DC.
Support for unmanaged VMware Tools - задачи SureBackup теперь поддерживают виртуальные машины с пакетами VMware Tools, которые установлены вручную.
Остальные улучшения Veeam Backup and Replication 6
Enhanced PowerShell support - расширены возможности PowerShell API, что позволяет управлять всеми настройками Veeam Backup. Все командлеты PowerShell были упрощены в плане синтаксиса (старый синтаксис также поддерживается). Появились маски в именах объектов, поиск объектов - все аналогично возможностям в консоли.
Log collection wizard - новый мастер, который собирает лог-файлы с защищенных хостов и подготавливает пакет, необходимый при обращении в техподдержку Veeam.
1-click automated upgrade - все компоненты продукта, включая те, что установлены на удаленной площадке (backup
proxy servers и backup repositories), могут быть просто обновлены с использованием мастера Upgrade wizard. При открытии консоли, Veeam Backup & Replication автоматически определяет компоненты решения, которые следует обновить.
Продукт Veeam Backup and Replication 6 должен быть доступен для скачивания с сайта Veeam ориентировочно в среду на странице загрузки продукта.
Несколько скриншотов. Восстановление файла резервной копии из результатов поиска в Enterprise Manager:
Настройки Traffic Throttling:
Мастер восстановления виртуальной машины Microsoftc Hyper-V:
Настройка бэкап-репозиториев:
Настройки Re-IP при восстановлении на резервной площадке:
Часто бывает, что от хоста ESX/ESXi нужно отвязать Datastore и LUN, на котором это виртуальное хранилище находится. При этом важно избежать ситуации All Paths Down (APD) - когда на хосте все еще остались пути к устройству, а самого устройства ему больше не презентовано. В этом случае хост ESX/ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути.
В этом случае из-за APD хоста начнут возникать задержки других задач (поскольку таймауты большие), что может привести к различным негативным эффектам вплоть до отключения хоста от vCenter.
ESX/ESXi 4.1
В версии ESX/ESXi 4.1 демон hostd проверяет том VMFS на доступность прежде чем слать туда команды ввода-вывода (I/Os) Но это не помогает для тех I/O, которые находятся в процессе в то время, когда случилась ситуация APD.
Как описано в KB 1015084, правильно отвязывать LUN с хоста ESX/ESXi 4.1 так (все делается на каждом из хостов):
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control) больше не используются для этого устройства.
Замаскировать LUN на хосте ESX/ESXi, следуя инструкциям KB 1009449 через модуль PSA (Pluggable Storage Architecture).
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESX/ESXi.
Удалить правила маскирования LUN, которые вы сделали на шаге 4 по инструкции в KB1015084.
Убедиться, что не осталось путей к устройству, после того, как вы проделали все эти операции.
Для ESX/ESXi 4.1 процесс достаточно сложный, теперь давайте посмотрим, как это выглядит в ESXi 5.
ESXi 5.0
В ESXi 5.0 появился новый статус Permanent Device Loss (PDL), то есть когда хост считает, что дисковое устройство уже никогда не будет снова подключено, а ситуация APD рассматривается как временный сбой, после которого хост снова увидит пути и устройство.
Чтобы избавиться от сложной процедуры отключения LUN от хостов ESXi, VMware сделала операции detach и unmount в интерфейсе vSphere Client и в командном интерфейсе CLI.
Вот тут можно найти unmount Datastore (но устройство продолжит быть доступным):
А вот тут находится detach для самого устройства:
Как описано в KB 2004605, чтобы у вас не возникло ситуации APD, нужно всего-лишь сделать detach устройства от хоста. Это размонтирует VMFS-том (если там есть какие-нибудь объекты - vSphere Client вам сообщит об этом).
Таким образом правильная последовательность отключения LUN в ESXi 5.0 теперь такова:
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control или Storage DRS) больше не используются для этого устройства.
Сделать detach устройства на хосте ESXi, что также автоматически повлечет за собой операцию unmount.
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESXi.
Ну и в качестве дополнительного материала можно почитать вот эти статьи:
Мы уже много рассказывали о продукте vGate R2, который позволяет защитить инфраструктуру от несанкционированного доступа и настроить ее в соответствии со стандартами и лучшими практиками на базе политик (в т.ч. ФЗ 152). Кроме того, у vGate R2 есть все необходимые сертификаты ФСТЭК, которые помогут вам пройти сертификацию в соответствующих органах. Мы много писали о работе с продуктом со стороны администратора (см. тут и тут), а сегодня опишем, как это выглядит со стороны пользователя.
Некоторые из вас, конечно же, как-то раз задумывались - а не открыть ли мне свой бизнес по сдаче в аренду виртуальных машин VMware vSphere? У каждого клиента будут свои виртуальные машины, я буду собирать с них помесячно плату, они уже никуда не соскочат, а мне останется лишь собирать деньги, да знай себе поддерживать инфраструктуру и наращивать мощности.
Я как человек в этом немного покрутившийся, могу вам сказать, что здесь не все так просто, и сам бы я такой бизнес профильным не сделал бы ни за что на свете. Но для тех, кого все-таки не оставляет эта идея, ниже приведены некоторые моменты об организации облака на основе решений VMware, виртуальные машины из которого вы можете предоставлять как услугу.
Начнем с того, что обычные лицензии VMware, которые вы покупаете у одного из партнеров или получаете как Internal Use Licenses, не позволяют вам сдавать виртуальные машины в аренду (внешним пользователям, не в своей организации) - это прямо запрещено пользовательским соглашением (EULA). Поэтому для таких дельцов придумана программа VSPP - VMware Service Provider Program (за само партнерство в программе платить не надо).
Программа VSPP направлена для сервис-провайдеров, телеком-операторов, интернет-провайдеров, поставщиков услуг, системных интеграторов и ИТ-подразделений корпораций, которые "продают" ИТ-ресурсы дочерним или аффилированным компаниям.
Эта программа позволяет вам получить некоторый пакет продуктов в рамках вашего партнерства с VMware по программе VSPP и начать предоставлять пользователям виртуальные машины (но не только!) в аренду, используя множество программных продуктов: vSphere, vCloud Director, vShield, View и многое другое. Всего есть несколько уровней партнерства по VSPP, у каждого из которых есть свои преимущества и требования.
Здесь нужно выделить 2 ключевых момента - это очки (points) и Aggregator (агрегатор) VSPP. Начнем с агрегатора. На самом деле вы не можете подписать контракт с VMware и начать сдавать в аренду ее машины и отчислять ей платежи. Это потому, что VMware ведет бизнес в каждой стране по своему и там ей нужны партнеры, которые посредством своих мутных схем и офшоров будут гонять бабло между, например, Россией, Кипром, ОАЭ и Америкой с одной стороны, а с другой - между юрлицом в России и российскими партнерами VMware.
Собственно, агрегатор - это тот же дистрибьютор, только касаемо облачных сервисов VMware. Но у него есть и некая техническая функция. Когда вы вписываетесь в VSPP, у вас в инфраструктуре vSphere развертывается специальное ПО на сервере vCenter, котороя смотрит сколько расходуется у вас ресурсов для виртуальных машин и посылает эти данные агрегатору. Делается это ежемесячно.
Далее агрегатор посылает эти данные в VMware на аудит, а сам выставляет вам счет, чтобы собрать бабло, которое дальше через офшоры и серые схемы потечет в VMware. В России таких агрегаторов несколько, и вы их найдете без труда.
Далее ключевой момент это очки (points), которые вы покупаете (а точнее, арендуете) ежемесячно, чтобы иметь право предоставлять некоторое количество услуг на базе продуктов VMware (чаще - виртуальных машин) в аренду. Самое важное тут то, что в большинстве случаев единицей тарификации является сконфигурированная оперативная память виртуальных машин (vRAM) - очки за 1 ГБ. Но есть и другие варианты тарификации для некоторых продуктов:
Но вас, скорее всего, интересует только Infrastructure as a Service (IaaS) - то есть, собственно, сдача виртуальных машин в аренду (то, что выделено красным). На сами цифры не смотрите - они американские и для нас неактуальные.
Для нас интересны вот эти 2 набора (эти цифры, вроде, актуальные):
VSPP Standard Bundle - это, по-сути, VMware vSphere 5 + Chargeback (для внутреннего биллинга) + vCloud Director (система управления датацентром с точки зрения облака - выделение ВМ и ресурсов, задание уровней сервиса, управление пользователями и т.п.). Для нас он стоит 5 очков в месяц за 1 ГБ памяти виртуальных машин (ниже я расскажу какой гигабайт). Второй VSPP Enterprise Bundle включает в себя еще и продукт vShield Edge для комплексной защиты периметра датацентра (см. подробнее тут и тут).
Теперь о тарификации этого самого гигабайта. Вы уже поняли, что единица стоимости - это 1 point, сколько он стоит в России я вам не скажу, но скажу, что в Америке 1 point = 1$. А суть лицензирования гигабайта такова:
Вы создаете виртуальные машины для аренды и выставляете им vRAM Reservation, но не менее 50% (требование VMware) от сконфигурированной памяти.
Максимально учитывается на одну ВМ - не более 24 ГБ.
Умножаете ваш бандл (например, для Standard - это 5 очков) на число vRAM ваших ВМ и на долю зарезервированных ресурсов (например, для 50% это, понятное дело, 0,5). Получаете общее количество очков в месяц, за которые вам надо платить агрегатору.
Выключенные ВМ не тарифицируются.
Как видно, у сервис-провайдера VSPP тоже есть некоторые права - вы можете гарантировать меньше ресурсов и меньше платить, либо обеспечить 100%-й SLA, но платить больше.
Смотрим на пример расчета:
Ну и каждый месяц агрегатор смотрит, сколько у вас набежало использованных очков, способствует продвижению уровня партнерства VSPP и выбиванию скидок за объем потребляемых поинтов. Вот тут есть хороший FAQ по программе VSPP, а тут - презентация.
Вкратце - это все. Тема у нас пока эта очень муторная. Если инетересно дальше - могу дать контакт с кем можно поговорить на эту тему. Ну а хотите купить виртуальные машины VMware в аренду - пожалуйста.
Несмотря на то, что в VMware vSphere Client диски виртуальных машин создаются уже выровненными относительно блоков системы хранения данных, многих пользователей платформы беспокоит, не выглядит ли их дисковая подсистема для ВМ таким образом:
Специально для таких пользователей, на сайте nickapedia.com появилась бесплатная утилита UBERAlign, которая позволяет найти виртуальные диски машин с невыровненными блоками и выровнять их по любому смещению.
Но самое интересное, что утилита UBERAlign работает еще и как средство, позволяющее уменьшать размер виртуальных дисков ВМ с "тонкими" дисками (thin provisioning), возвращая дисковое пространство за счет удаленных, но не вычищенных блоков.
Скачать UBERAlign можно по этой ссылке (а вот тут в формате виртуального модуля OVA), полный список возможностей утилиты можно найти тут (там еще несколько видеодемонстраций).
Многие пользователи VMware vSphere знают, что для кластера HA раньше была настройка das.failuredetectiontime - значение в миллисекундах, которое отражает время, через которое VMware HA признает хост изолированным, если он не получает хартбитов (heartbeats) от других хостов и isolation address недоступен. После этого времени срабатывает действие isolation response, которое выставляется в параметрах кластера в целом, либо для конкретной виртуальной машины.
В VMware vSphere 5, в связи с тем, что алгоритм HA был полностью переписан, настройка das.failuredetectiontime для кластера больше не акутальна.
Теперь все работает следующим образом.
Наступление изоляции хост-сервера ESXi, не являющегося Master (т.е. Slave):
Время T0 – обнаружение изоляции хоста (slave).
T0+10 сек – Slave переходит в состояние "election state" (выбирает "сам себя").
T0+25 сек – Slave сам себя назначает мастером.
T0+25 сек – Slave пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+30 сек – Slave объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Наступление изоляции хост-сервера ESXi, являющегося Master:
T0 – обнаружение изоляции хоста (master).
T0 – Master пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+5 сек – Master объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Как мы видим, алгоритм для мастера несколько другой, чтобы при его изоляции остальные хосты ESXi смогли быстрее начать выборы и выбрать нового мастера. После падения мастера, новый выбранный мастер управляет операциями по восстановлению ВМ изолированного хоста. Если упал Slave - то, понятное дело, восстановлением его ВМ управляет старый мастер. Помним, да, что машины будут восстанавливаться, только если в Isolation Responce стоит Shutdown или Power Off, чтобы хост мог их погасить.
Интересный момент обнаружился на блогах компании VMware. Оказывается, если вы используете в кластере VMware HA разные версии платформы VMware ESXi (например, 4.1 и 5.0), то при включенной технологии Storage DRS (выравнивание нагрузки на хранилища), вы можете повредить виртуальный диск вашей ВМ, что приведет к его полной утере.
In clusters where Storage vMotion is used extensively or where Storage DRS is enabled, VMware recommends that you do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.0 host, and vSphere HA restarts the virtual machine on a host with a version prior to ESXi 5.0. While the virtual machine might power on, any subsequent attempts at snapshot operations could corrupt the vdisk state and leave the virtual machine unusable.
По русски это выглядит так:
Если вы широко используете Storage vMotion или у вас включен Storage DRS, то лучше не использовать кластер VMware HA. Так как при падении хост-сервера ESXi, HA может перезапустить его виртуальные машины на хостах ESXi с другой версией (а точнее, с версией ниже 5.0, например, 4.1). А в это время хост ESXi 5.0 начнет Storage vMotion, соответственно, во время накатывания последовательности различий vmdk (см. как работает Storage vMotion) машина возьмет и запустится - и это приведет к порче диска vmdk.
Надо отметить, что такая ситуация, когда у вас в кластере используется только ESXi 5.0 и выше - произойти не может. Для таких ситуаций HA и Storage vMotion полностью совместимы.
Многие задаются вопросом - а как себя поведет кластер VMware HA в vSphere 5 при отключении всех хост-серверов VMware ESXi 5 (например, отключение электричества в датацентре)?
Алгоритм в этом случае таков:
1. Все хосты выключаются, виртуальные машины на них помечаются как выключенные некорректно.
2. Вы включаете все хосты при появлении питания.
3. Между хостами ESXi происходят выборы Master (см. статью про HA).
4. Master читает список защищенных HA виртуальных машин.
5. Master инициирует запуск виртуальных машин на хостах-членах кластера HA.
Надо отметить, что восстановлении VMware HA смотрит на то, какие из них были выключены некорректно (в случае аварии), и для таких ВМ инициирует их запуск. Виртуальные машины выключенные корректно (например, со стороны администратора) запущены в этом случае не будут, как и положено.
Отличия от четвертой версии vSphere здесь в том, что вам не надо первыми включать Primary-узлы HA (для ускорения восстановления), поскольку в vSphere 5 таких узлов больше нет. Теперь просто можете включать серверы в произвольном порядке.
Многие из вас знают, что у компании VMware есть утилита VMmark, которая позволяет измерять производительность различных аппаратных платформ (и работающих в ВМ приложений), когда на них работает платформа виртуализации VMware vSphere. При этом можно сравнивать различные платформы между собой в плане производительности.
Сейчас компания VMware решила сделать несколько иначе: на одном и том же сервере Dell Power Edge R310 поставить vSphere 4, посчитать производительность, а потом сделать то же самое с vSphere 5 на этом же сервере. При тестировании было 4 типа нагрузки с нарастанием до насыщения утилизации сервера по CPU и получились вот такие результаты:
В результате ESXi 5.0 обогнал ESXi 4.1 на 3-4% очкам в зависимости от нагрузки (линии же CPU - практически одинаковы). Но самое интересное, что при росте нагрузки машин на сервер ESXi 5 позволил поддерживать виртуальных машин на 33% больше, чем ESXi 4.1 при условии соблюдения требований к качеству обслуживания для виртуальных машин - правый столбик (как это оценивалось не очень понятно). При этом ESXi 5.0 позволял выполнять в два раза больше операций с инфраструктурой в кластере, чем его предшественник (см. ниже).
Также VMware померила время отклика различных приложений и вычислила их задержки (latency), а также latency для операций инфраструктуры (vMotion, Storage vMotion и VM Deploy). Вышло так (показано в нормализованном виде):
Обратите внимание, что vMotion и Storage vMotion - стали работать значительно быстрее (о том, как это было сделано - тут). Вот как раз за счет низкого latency ESXi 5 и смог обеспечить поддержку на 33% больше виртуальных машин при условии соблюдения QoS.
Продолжаем разговор о решении номер 1 для создания отказоустойчивых хранилищ StarWind Enterprise HA, которое наиболее оптимально подходит как раз для малого и среднего бизнеса, где не хочется тратить деньги на дорогостоящее хранилище и его обслуживание. Берете просто 2 сервера, на нем поднимаете виртуальные машины и там же отказоусточивое хранилище (при отказе работает без простоя ВМ). На Hyper-V делается это с помощью StarWind Native SAN for Microsoft Hyper-V, а для VMware можно сделать так на StarWind 5.7.
Второй - это статья "Кластер Hyper-V 2008 R2 на коленке", где чувак взял и поднял кластер Hyper-V R2 с Live Migration на базе iSCSI-хранилища StarWind, используя обычные ПК.
В общем, почитайте, СМБ-шники.
Таги: StarWind, HA, SMB, Whitepaper, vSphere, ESXi, Microsoft, Hyper-V
На мероприятии UK VMware User Group Julian Wood представил интересную презентацию, которая суммирует необходимые дествия и процедуры по миграции с платформы VMware vSphere 4 на vSphere 5, включая хост-серверы ESX / ESXi, vCenter (включая его компоненты), виртуальные машины, VMware Tools и тома VMFS.
Один из лучших материалов, обобщающих информацию на тему миграции на vSphere 5.
Копенгаген, Дания, 31 октября 2011 – Компания VMware, мировой лидер в области виртуализации и облачных вычислений, анонсировала на европейском форуме VMworld 2011 выпуск нового VMware vCenter™ Protect Essentials Plus и обновлений для сервиса VMware Go Pro™, упрощающих управление ИТ-процессами для представителей малого и среднего бизнеса (СМБ). Таги:
Продукт VMware Go Pro (о котором мы уже писали) был разработан совместно компаниями Shavlik и VMware и предназначен для упрощения миграции на виртуальную инфраструктуру VMware в небольших организациях и управления ей через веб-браузер. С помощью служб Go можно развертывать новые виртуальные машины на базе бесплатного продукта VMware ESXi (теперь это VMware Hypervisor) и даже делать некоторые процедуры по управлению виртуальной и физической инфраструктурой. Он поставляется в бесплатном издании (Go) и коммерческом (Go Pro). Надо отметить, что продукт поставляется как SaaS-решение и имеет сервисы не только для виртуализации.
Бесплатная версия VMware Go предоставляет следующую функциональность:
IT Advisor - решение для обследования инфраструктуры на предмет виртуализации, которое предоставляет рекомендации по миграции систем.
Мастер установки, настройки и управления бесплатными хост-серверами vSphere hypervisors (ESXi 5)
Создание новых виртуальных машин Virtual Machines
Список программных компонентов в виртуальной среде
Список оборудования
Сканирование систем на обновления, включая ПО не только от Microsoft
Служба Help Desk для управления инцидентами на базе тикетов
Коммерческая версия Go Pro добавляет в решение следующую функциональность:
Управление лицензиями на ПО
Учет оборудования
Развертывание обновлений и патчей
Портал Help Desk для пользователей вашей организации и управление учетными записями
Поддержка SaaS-решения
Возможность использования платной версии продукта VMware Go Pro появится уже до конца года по цене от $12 за управляемую систему в год (для американцев).
Второй продукт - это VMware vCenter Protect Essentials Plus, который раньше назывался Shavlik NetChk Protect. Он позволит управлять обновлениями операционных систем и приложений в физических и виртуальных средах (которое для виртуальных машин раньше было в vSphere как раз от Shavlik). Поставляться он будет в двух издания - Essentials и Essentials Plus (отличия тут).
VMware vCenter Protect Essentials имеет следующие возможности:
Автоматическое сканирование и обновление выключенных виртуальных машин и шаблонов для ПО различных вендоров (например, Microsoft, Adobe, Java)
Работа с группами виртуальных машин
Поиск по domain, organizational unit, machine name, IP-адресу или диапазону IP
Запуск задач по обновлению систем в определенное время и по условиям
Поддержка патчинга для custom-приложений
Накат частных патчей от Microsoft
Custom Patch File Editor - для обновления внутренних продуктов компании
Machine View - информация о системах и их статусе
Поддержка скриптов, например, для сбора логов агентами и др.
Работа с агентами и без них
Поддержка резервного копирования и отката через механизм снапшотов
В решении VMware vCenter Protect Essentials Plus добавляются:
Антивирус на базе Sunbelt VIPRE Enterprise Antivirus and Antispyware
Управление электропитанием серверов через Wake-on LAN (WoL)
Управление конфигурациями систем (Configuration Management)
Расширенная поддержка сценариев, Microsoft PowerShell для автоматизации задач
Возможность использования продукта VMware vCenter Protect Essentials появится уже до конца года по цене от $57 за управляемый сервер в год и от $36 за рабочую станцию (для американцев).
Распространяться оба продукта будут, как я понимаю, через обычных реселлеров.
Решение Veeam nworks MP 5.7 добавляет в область мониторинга инфраструктуру VMware, позволяя поддерживать единообразие политик и правил для
System Center и отслеживать состояние всей инфраструктуры с помощью уже имеющейся консоли Operations Manager.
Новые возможности Veeam nworks Management Pack 5.7:
Полная поддержка VMware vSphere 5.0
Обработка более 500 событий и более 160 метрик в виртуальной инфраструктуре
Новые виды отчетов, включая отчет по виртуальным машинам, которым выделено слишком много ресурсов
Новые типы представлений (более 20) отчетных данных и обзорные экраны (dashboards)
Поддержка больших инсталляций vSphere
Мониторинг оборудования напрямую с хостов ESXi через интерфейс CIM
Оптимизация производительности и обнаружения объектов
Решение Veeam nworks SPI 5.7 добавляет в область мониторинга инфраструктуру VMware в консоль HP Operations Manager.
Новые возможности Veeam nworks Smart Plug-in 5.7:
Полная поддержка VMware vSphere 5.0
Поддержка HP Operations Manager 9.0 for Windows
ПоддержкаHP Performance Agent 11
Поддержка последней версии Veaam Business View для организации мониторинга по бизнес-объектам
Поддержка больших инсталляций vSphere
Динамическая группировка кластеров, хостов, хранилищ и виртуальных машин
Мониторинг оборудования напрямую с хостов ESXi через интерфейс CIM
Решения Veeam nworks Management Pack и Smart Plug-in 5.7 будут доступны для загрузки в течение 60 дней. Пока можно скачать бета-версии и отслеживать новости на этой странице.
Таги: Veeam, nworks, Update, VMware, vSphere, Monitoring, Microsoft, HP
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Пусть повисит тут эта инструкция - полезно и часто ищут. SSH на хосте VMware ESXi 5 можно включить двумя способами - через консоль сервера ESXi и через vSphere Client. Надо отметить, что в отличие от предыдущих версий ESX/ESXi, доступ по SSH к хосту ESXi 5.0 полностью поддерживается и является нормальным рабочим процессом.
1. Включение SSH на ESXi 5 через консоль.
Нажимаем <F2> в консоли:
Вводим пароль root и переходит в пункт "Troubleshooting Options":
Выбираем пункт "Enable SSH":
2. Включение SSH на ESXi 5 через vSphere Client.
Переходим на вкладку "Configuration", выбираем пункт "Security Profile" и нажимаем "Properties":
Выбираем сервис SSH и нажимаем "Options":
Устанавливаем режим запуска сервиса SSH на ESXi и включаем его кнопкой Start:
После включения SSH на ESXi 5.0 у вас появятся следующие предупреждения в vSphere Client для хоста:
SSH for the host has been enabled
Если вы включали ESXi Shell, то будет сообщение:
ESXi Shell for the Host has been enabled
Чтобы их убрать, нужно сделать так:
Выбираем нужный хост ESXi.
Переходим в категорию "Advanced Settings" в разделе "Software" на вкладке "Configuration".
Переходим в раздел UserVars > UserVars.SupressShellWarning.
Меняем значение с 0 на 1.
Нажимаем OK.
Но, вообще говоря, так делать не надо, так как SSH лучше выключать в целях безопасности на время, когда вы им не пользуетесь.
Ну и как войти по SSH на ESXi 5 пользователе root читаем тут - ничего не изменилось.
Мы уже много рассказывали о продукте vGate R2 от компании Код Безопасности (см. наш раздел), который позволяет защитить виртуальную инфраструктуру от несанкционированного доступа, разделить полномочия администраторов и настроить компоненты vSphere в соответствии с лучшими практиками и стандартами (в том числе, российскими). Сегодня мы рассмотрим средства контроля целостности vGate.
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
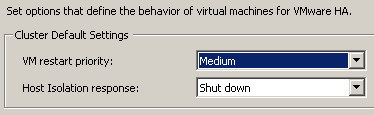
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
В первой части статьи мы уже рассматривали наиболее оптимальную конфигурацию средства VMware vSphere Storage Appliance для создания отказоустойчивого кластера хранилищ из трех хостов и описали, что происходит с хранилищами при отказе сети синхронизации (Back-End Network). Во второй части статьи мы расскажем о том, как конфигурация VSA отрабатывает отказ сети управления и экспорта NFS-хранилищ (Front-End).
Мы уже писали о новой версии платформы для виртуализации настольных ПК предприятия VMware View 5, которая имеет множество новых улучшений, позволяющих говорить о возможности внедрения решения в промышленных масштабах.
Как известно, при использовании виртуальных ПК существенно увеличивается риск утери или порчи данных пользовательской инфраструктуры, поскольку теперь десктопы централизованы в ЦОД и появляются различные SPOF-точки отказа (например, система хранения данных). Кроме того, возрастает риск утери десктопа вследствие неправильных кофигураций серверной инфраструктуры или дискового массива. В связи с этим важным оказывается вопрос резервного копирования виртуальных ПК, которому никто, почему-то, не уделяет значения. А вопрос действительно важный, и сложных моментов там хватает: конфигурация View Connection Server, View Composer, бэкапы связанных клонов и прочее.
Компания VMware выпустила очень нужный документ "VMware View Backup Best Practices", который рекомендуется почитать всем тем, кто планирует внедрение решения VMware View или его масштабирование из существующего пилота:
Сначала нам описывают инфраструктуру VMware View с точки зрения компонентов, которые нуждаются в резерировании:
Потом показывают структуру хранилищ:
Потом говорят о том, для каких компонентов необходимо производить резервное копирование.
Основные компоненты (помимо виртуальных машин):
View Connection Server
View Composer (если развернут)
vCenter server и хосты ESX/ESXi
Служба Active Directory
Если говорить о базах данных, то их вот сколько:
Хранилище View Connection Server AD-LDS
БД View Composer для событий (Events - если развернута)
БД vCenter server
Какие еще компоненты могут быть, которые нужно резервировать:
Репозиторий ThinApp, сконфигурированный на общей шаре
Хост View Transfer Server для офлайн-десктопов
База данных
View Error Log
В резервном копировании не нуждается Security Server (он не хранит изменяющихся данных), реплики View Connection Server и сторонние серверы управления VDI-инфраструктурой.
Резервное копирование виртуальных ПК на платформе vSphere. Производится аналогично бэкапу ВМ и конфигураций хостов для серверных нагрузок (лучше всего использовать Veeam Backup and Replication)
Резервное копирование хранилища View Connection Server AD-LDS
Бэкап базы данных View Composer
Бэкап базы vCenter
Для резервирования хранилища AD-LDS на Connection Server используется утилита vdmexport:
Этот файл ldf будет содержать конфигурацию LDAP для View.
Для базы данных View Composer можно использовать встроенные средства бэкапа SQL Server (сначала останавливаем службу View Composer Service).
Лучше если и Connection Server и Composer+vCenter будут в виртуальных машинах - тогда их проще будет восстанавливать вместе с базами (если они не внешние). Как бэкапить базу данных VMware vCenter должен знать любой администратор, обслуживающий vSphere как платформу.
Последовательность восстановления инфраструктуры View выглядит так:
Восстанавливаем базу vCenter
Восстанавливаем базу Composer (если база восстанавливается к по-новой установленному эксземпляру Composer, нужно прочитать
http://www.vmware.com/pdf/view45_admin_guide.pdf на странице 26 для настройки контейнера RSA-ключа)
Восстанавливаем хранилище View Connection Server AD-LDS на новой или старой инсталляции:
Stateful virtual desktops (данные сохраняются после выхода)
Stateless virtual desktop (данные не сохраняются после выхода)
Для связанных клонов все непросто - их можно бэкапить, например, с помощью Veeam Backup, однако восстанавливаются они только как индивидуальные десктопы. То есть их нужно сначала восстановить как ВМ на VMware vSphere, а потом назначить в VMware View как dedicated-десктоп.
Stateful-виртуальные ПК предлагается бэкапить и восстанавливать как обычные виртуальные ПК, а Stateless - в резервном копировании не нуждаются, поскольку там никаких критичных данные нет, такой десктоп может быть развернут по требованию из базового образа, а приложения в нем публикуются, например, с помощью ThinApp (но User Data-диск бэкапить необходимо, если он используется).
Также в документе приводятся основные рекомендации по частоте резервного копирования компонентов VMware View:
Вообще вся эта тема с резервным копированием виртуальных ПК VMware View кажется очень муторной. Пора бы уже какому-нибудь вендору выпустить специализированное решение для этой задачи. А как вы с ней справляетесь в своей инфраструктуре?
Многие из вас используют продукт номер 1 для создания отказоустойчивых хранилищ StarWind Enterprise, позволяющий предоставлять общие хранилища для виртуальных машин через iSCSI. Это очень хорошая технология для небольших компаний и филиалов, использующих VMware vSphere, но не могущих себе позволить полноценную систему хранения с дублированными аппаратными компонентами. Напомним, что скоро продукт будет доступен для двухузловой конфигурации Microsoft Hyper-V, а также выйдет версия StarWind 5.8, где обещают еще больше нововведений.
Некоторые пользователи применяют доступ к таргетам iSCSI для StarWind изнутри виртуальных машин (например, можно использовать бесплатное издание StarWind). Однако с VMware vSphere 5 и адаптером vmxnet3 обнаружилась интересная проблема - согласно KB 2006277, драйвер vmxnet3 из комплекта vSphere 5 некорректно работает с большими кадрами Jumbo Frames. Это приводит к деградации производительности и потере сетевого соединения.
Какие есть выходы:
Использовать драйвер vmxnet3 из комплекта VMware Tools для версии vSphere 4.x (можно загрузить тут)
Использовать виртуальный сетевой адаптер vmxnet2 (Enhanced) или E1000 из комплекта vSphere 5
Надо отметить, что при соединении серверов ESXi 5 с хранилищами StarWind с настроенными Jumbo Frames полностью поддерживается. Также все работает и в конфигурации с томами RDM для виртуальных машин в режиме физической и виртуальной совместимости.
Компания VMware работает над решением проблемы для адаптера vmxnet3 и Jumbo Frames при работе из гостевой ОС. Спасибо Константину Введенскому за новость.
Мы уже писали о том, что такое виртуальный модуль VMware VSA, и как он работает в случае отключения сети синхронизации между хост-серверами VMware ESXi. Сегодня приведем несколько полезных материалов.
Во-первых, это документ "Performance of VSA in VMware Sphere 5", рассказывающий об основных аспектах производительности продукта. В нем приведен пример тестирования VSA на стенде с помощью различных инструментов.
Всем интересующимся производительностью VSA для различных типов локальных хранилищ и рабочих нагрузок в виртуальных машинах документ рекомендуется к прочтению.
Во-вторых, появилось интересное видео о том, как VMware VSA реагирует на отключение сети синхронизации хранилищ и сети управления VSA.
Отключение Front-end сети (управление виртуальным модулем и NFS-сервер):
Отключение Back-end сети (зеркалирование хранилищ, коммуникация в кластере):
Ну и, в-третьих, хочу напомнить, что до 15 декабря при покупке VMware vSphere 5 Essentials Plus + VSA вместе действует скидка 40% на модуль VSA.
Таги: VMware, VSA, Performance, Storage, vSphere, HA, SMB, Video
Пост в рамках заказанной вами рубрики "Что почитать?". Компания VMware на прошедшей неделе выпустила несколько очень нужных, полезных, а главное интересных для чтения документов. Вот они:
Документ описывает лучшие практики по переходу на VMware vSphere 5 с предыдущих версий, включая хост-серверы VMware ESXi, сервер vCenter и его базу данных. См. также нашу серию статей о миграции на vSphere 5.
В документе описаны основные рабочие процессы по управлению сервером виртуализации VMware ESXi 5, включая интерфейс vCLI, PowerCLI, управление через SSH и многое другое. Документ будет полезен многим, особенно пользователям бесплатного ESXi и изданий Essentials.
Самый нужный документ для тех, кто планирует внедрение инфраструктуры виртуальных ПК VMware View 5 в условиях высокой нагрузки на канал. В документе рассматривается тонкая настройка протокола PCoIP с помощью групповых политик, все с картинками - просто и понятно. Например, выставление maximum frame rate в 15 и maximum initial image quality в диапазоне 70-80 уменьшает требование к каналу в 2-4 раза при сохранении приличного качества картинки при просмотре видео.
Этот документ уже сфокусирован на производительности решения VMware View 5 в целом. Приведены примеры тестирования решения для различных настроек протокола PCoIP и других компонентов.
Продолжение обзора новой документации не заставит себя долго ждать.
Как вы знаете, не так давно вышла новая версия решения для виртуализации настольных ПК VMware View 5 с полной поддержкой VMware vSphere 5. Поэтому необходимо отметить, что старые версии VMware View 4.x (включая View Manager и View Composer) не поддерживаются на платформе vSphere 5. Об этом написано в KB 2006216:
No version of VMware View Manager 4.x (including Composer 2.6 and earlier) is compatible with vSphere 5 or its associated products
Кстати, для проверки совместимости различных продуктов VMware на ее сайте есть полезный инструмент VMware Product Interoperability Matrix. Из него мы можем, например, узнать какими версиями ПО хост-серверов VMware ESX/ESXi могут управлять различные версии vCenter:
То есть, мы видим, что vCenter 5.0 почему-то не может управлять хостами ESX/ESXi 4.0 Update 2, хотя U1 и U3 подходят. Также хорошая опция в этом инструменте - "Solution/Database Interoperability". Там можно узнать какие версии СУБД поддерживаются тем или иным продуктом.
Ну и вариант Solution Upgrade Path также может оказаться кому-то полезным:
Продолжаем вам рассказывать о средстве номер 1 для обеспечения информационной безопасности VMware vSphere - vGate R2 от Кода Безопасности. Напомним, что это средство позволяет автоматически настраивать компоненты vSphere в соответствии с регламентами и стандартами, а также обеспечивать защиту от несанкционированного доступа.
Сегодня мы поговорим о защите персональных данных (ПДн), которая является головной болью специалистов службы ИБ предприятия (ФЗ 152). Как многие из вас знают, при автоматизированной обработке ПДн защищенность информационной системы при использовании технологий виртуализации должна соответствовать требованиям российского законодательства.
В этой сфере есть несколько законов, постановлений и руководящих документов, которые актуальны на сегодняшний день:
Все эти документы не делают различия между физической и виртуальной средой. При этом в виртуальной инфраструктуре vSphere есть очень много новых рисков ИБ, о которых может не знать важа служба ИБ предприятия. Кроме того, в этих документах требования, зачастую, весьма неконкретны, поэтому непонятно, как их вообще выполнять, учитывая неоднозначность толкования.
Например: согласно документу ФСТЭК нужно регистрировать вход-выход пользователей из системы, которая имеет доступ к ПДн. Очевидно, что это может быть виртуальная машина с этой системой. Но к ПДн имеет доступ также гипервизор хост-сервера (в том числе к выключенным машинам) - и значит операции по работе с ним (например, вход в консоль ESX / ESXi) также надо правильно регистрировать.
Еще пример: требования к очистке (обнулению, обезличиванию) освобождаемых областей оперативной памяти информационной системы и внешних накопителей
в условиях виртуальной среды также должны быть дополнены такими операциями, как очистка освобождаемых областей оперативной памяти после завершения работы ВМ и дисков виртуальных машин при их удалении.
Наиболее жесткие требования к обеспечению
защиты персональных данных предъявляются к информационным системам персональных данных
(ИСПДн) класса К1, для которых процедура оценки соответствия является обязательной, а использу-
емые технические средства защиты информации
должны иметь сертификат ФСТЭК по уровню не ниже НДВ 4.
К таким организациям относятся медицинские учреждения (данные о состоянии здоровья - категория 1), а также финансовые и телекоммуникационные компании. Российское законодательство любые организации, осуществляющие обработку персональных
данных, признает оператором персональных данных.
А теперь подумайте, как вручную настроить конфигурацию виртуальной инфраструктуры vSphere, чтобы она соответствовала всем руководящим документам? Ведь сама vSphere имеет сертификат ФСТЭК только для версии vSphere 4.0 Update 1 и у нее нет сертификата по НДВ, что автоматически делает ее средства обеспечения ИБ неприемлемыми для ПДн категории К1 (то есть всех медучреждений, где в ВМ хранятся данные о пациентах). И даже если вы сами сможете настроить все правильно, то представляете каковы будут эксплуатационные затраты на настройку при развертывании новых систем или изменении старых. А помимо общих документов, есть еще и специфические отраслевые стандарты вроде СТО БР ИСПДн (Банк России) и прочие.
Соответственно вам нужно автоматизированноесредство vGate R2, у которого есть все необходимые бумаги и сертификаты. Например, в vGate R2 есть политики для настройки инфраструктуры vSphere по российским РД и стандартам (СТО БР ИСПДн, АС разных классов, шаблон политик под ФЗ 152 и др).
Что вы можете почитать на тему защиты ПДн в виртуальной инфраструктуре с помощью vGate R2:
Мы уже писали о новом продукте VMware vSphere Storage Appliance (VSA), который позволяет создать кластер хранилищ на базе трех серверов (3 хоста ESXi 5 или 2 хоста ESXi 5 + физ. хост vCenter), а также о его некоторых особенностях. Сегодня мы рассмотрим, как работает кластер VMware VSA, и как он реагирует на пропадание сети на хосте (например, поломка адаптеров) для сети синхронизации VSA (то есть та, где идет зеркалирование виртуальных хранилищ).
Таги: VMware, VSA, vSphere, Обучение, ESXi, Storage, HA, Network
С выпуском платформы виртуализации VMware vSphere 5 в ESXi 5.0 появилась возможность запуска вложенных 64-битных виртуальных машин, в том числе Hyper-V. Выглядит это так:
На физическом сервере (или даже виртуальном, созданном в VMware Workstation) вы устанавливаете ESXi 5.0
Создаете виртуальную машину с гостевой ОС Windows Server (включая восьмую версию)
В этой ВМ с Windows Server включаете роль Hyper-V и устанавливаете там виртуальные машины, которые работают
Аналогичный трюк можно провернуть, установив ESXi в ESXi и на последнем поставить 64-битные виртуальные машины (ранее можно было только 32-битные). Все это открывает широкие возможности по тестированию VMware vSphere 5 и Hyper-V, включая возможности распределенных служб (кластеры HA/vMotion и Live Migration). При этом не нужно иметь даже сервер в своем распоряжении - достаточно будет обычного ПК с VMware Workstation.
Для эмуляции возможностей hardware-assisted virtualization (HV), которые требуются для работы вложенных гипервизоров Hyper-V и ESXi (делается это за счет виртуализации 64-битных инструкций VT-x или AMD-V), вам потребуется хост с соответствующими аппаратными характеристиками процессора (Intel VT или AMD-V сейчас есть практически во всех процессорах). Поддержка такой возможности в продуктах VMware называется Virtualized HV.
По умолчанию возможности Virtualized HV на хосте ESXi 5.0 отключены. Чтобы их включить, на физическом или виртуальном хосте VMware ESXi в файл /etc/vmware/config нужно добавить строчку:
vhv.allow = "TRUE"
Перезагрузка для применения этой возможности хосту не нужна.
Чтобы узнать включена эта возможность или нет, нужно выполнить команду для лога виртуальной машины (по выводу вы поймете статус):
grep "monitorControl.vhv" vmware.log
Далее просто создавайте вложенные VMware ESXi 5 (не забыв указать в качестве гостевой ОС ESXi). Помните, что Virtual Hardware Version должна быть 8 (на самом деле можно и с 7-й версией, но нужно сделать дополнительные шаги).
Чтобы поставить виртуальную машину с Hyper-V нужно еще добавить следующую строчку в vmx-файл для этой ВМ:
hypervisor.cpuid.v0 = FALSE
Это не даст понять гостевой ОС, что она работает в виртуальной машине. Если этого не сделать, то Hyper-V R2 выдаст такую ошибку:
Failed to create partition: Unspecified error (0x80004005)
А Hyper-V R3 вот такую:
Hyper-V cannot be installed: A hypervisor is already running.
Ну а дальше устанавливаете Windows Server, включаете роль Hyper-V, создаете виртуальные машины и запускаете их. Что касается вложенности - то, говорят, на 4-м уровне уже начинаются тормоза, которые не дают приемлемо работать, а до этого уровня - пожалуйста.
В этой статье описан интересный вариант использования приведенной вомзожности - создание кластера VMware vStorage Appliance (VSA) на базе виртуальных ESXi 5.0.
Кстати, если вы хотите, наоборот, запустить виртуальный ESXi 5.0 на физическом хосте Hyper-V, то в vmx-файл с виртуальным ESXi нужно добавить строчку:
vmx.allowNested = TRUE
Это позволит запускать вложенные ВМ на таком виртуальном ESXi 5.0 под управлением Hyper-V.
Как мы уже писали, с 22 августа этого года существенно поднялись цены на все продукты линейки VMware vSphere с выходом пятой версии. Однако только в период с сегодняшнего дня и до 21 сентября включительно мы еще можем постараться принять от вас заказы на четвертую версию vSphere по старым ценам, которая у вас сразу же станет бесплатно пятой версией в соответствии с таблицей обновления по приобретенной подписке:
То есть, я предлагаю вам купить VMware vSphere 5 значительно дешевле (в некоторых случаях - до 70%). А теперь обратите внимание на следующую табличку:
Если вы в эти 3 дня успеете купить VMware vSphere 4 Advanced Acceleration Kit по старой цене (от четверки), то вы сразу получите бесплатно пятую версию VMware vSphere 5 Enterprise Acceleration Kit, которая уже стоит на >60% дороже. Пример расчета по прайс-листовым ценам:
VMware vSphere 5 Enterprise Acceleration Kit for 6 processors + поддержка (SnS) на 1 год = $22 743,50 + $7 165,31 = $29 908,81
VMware vSphere 4 Advanced Acceleration Kit for 6 processors with vCenter Standard + поддержка на 1 год = 14 294,50 + 3 542,24 = $17 836,74
То есть, продукт-то один и тот же, а цены разные (мы еще и скидку сделаем!). Пишите: pr@vmc-company.ru. Этот email работает круглосуточно.
P.S. Не тупите, покупайте. Эта скидка даже больше, чем по купонам на Групоне.

 RSS
RSS